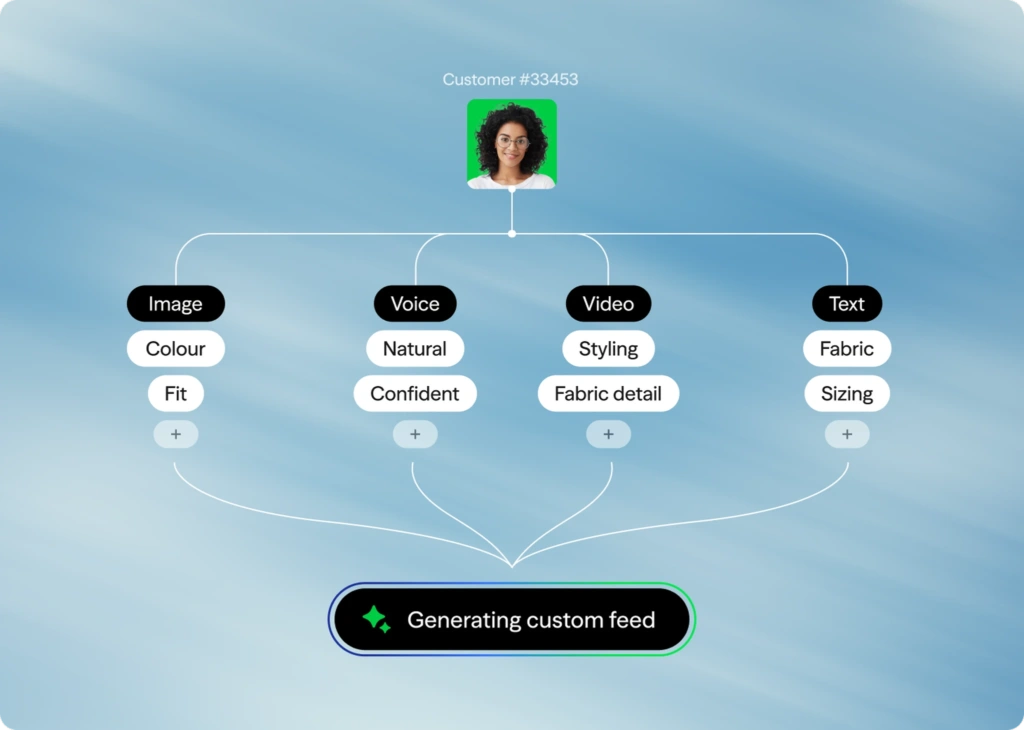
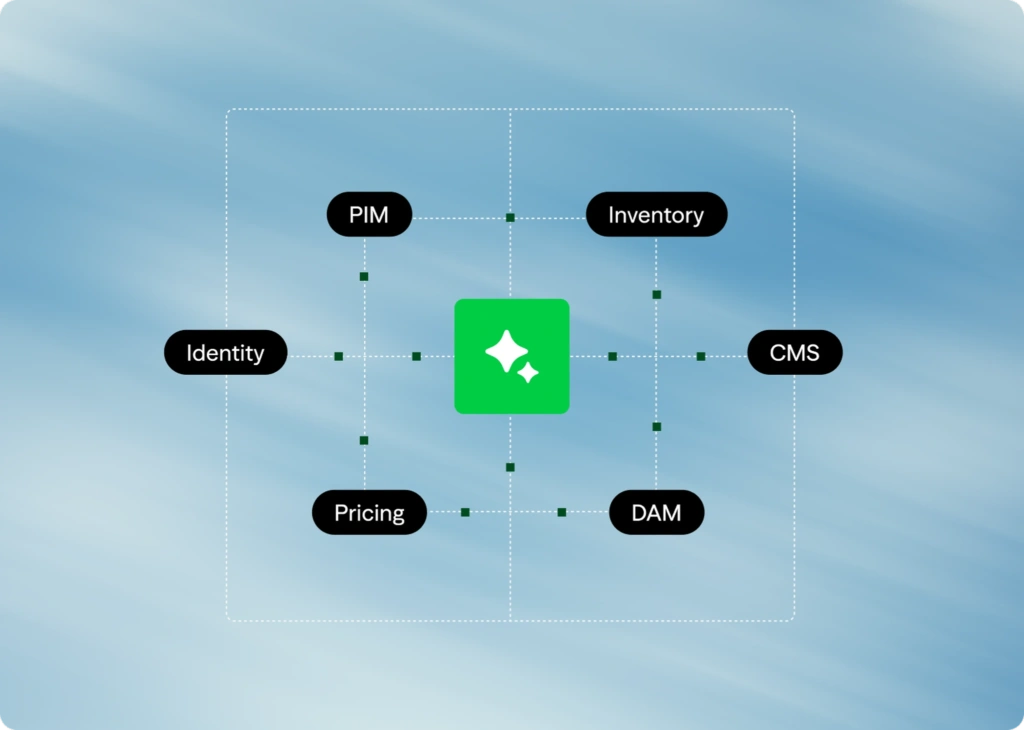
Multimodal AI is redefining how customers discover, evaluate, make choices and purchase products, making the shopping experience easier than ever. But what’s effortless for customers is increasingly complex for retailers. Delivering these interactions requires specialized vision models, high-quality product data, multimodal fusion layers and real-time inference pipelines.
Solvd makes that complexity feel simple. By helping retailers harness voice, vision, AR and generative intelligence, we enable them to increase conversion, deliver lower return rates, accelerate SKU activation and unlock lower cost-to-serve through more automated and personalized experiences across every channel.